GPT-4o Mini vs. Claude 3.5 Sonnet: A Detailed Comparison for Developers
On July 18, 2024, OpenAI introduced GPT-4o mini, the most cost-efficient AI model released yet designed by OpenAI. GPT-4o mini showed impressive capabilities at a fraction of the cost of Claude 3.5 Sonnet, being roughly 20x cheaper for input tokens and 25x cheaper for output tokens.

Despite being a smaller model, GPT-4o mini performs surprisingly well on many benchmarks, often standing nearly on par with larger models like Claude 3.5 Sonnet. This cost-effectiveness makes GPT-4o mini attractive and challenges the assumption that smaller models necessarily perform worse than larger, more expensive models.
In this blog, we will compare GPT-4o Mini with Claude 3.5 Sonnet, highlighting the key significant differences in capabilities, performance, and use cases.
GPT-4o Mini vs. Claude 3.5 Sonnet at a Glance
| gpt-4o mini | claude 3.5 sonnet | |
|---|---|---|
| Providers | OpenAI | Anthropic |
| Context Window | 128,000 tokens | 200,000 tokens |
| Max Output Tokens | 16,000 tokens | 4,096 tokens |
| Release Date | July 18, 2024 | June 20, 2024 |
| Knowledge Cutoff | October 2023 | April 2024 |
| Open-Source | No | No |
| Pricing | $0.15 / million input tokens, $0.60 / million output tokens | $3.00 / million input tokens, $15.00 / million output tokens |
| Model Size | 1.3B | 175B |
| Multi-Modal | Yes, both text and images | Yes, both text and images |
| Speed | 126 output tokens / second | 72 output tokens / second |
| Recommended For | High-volume application and where cost-eficiency is important. | Applications that require accurate and complex reasoning, or handling large document as inputs. |
For more details, visit Helicone's free model comparison tool.
Comparing Reasoning Capabilities
The official benchmarks compare GPT-4o and Claude 3.5 Sonnet, but not GPT-4o Mini. For a more accurate comparison, we will compare Claude 3.5 Sonnet and GPT-4o Mini in two parts.
Step 1: Claude 3.5 Sonnet vs. GPT-4o
Here's the official benchmark provided by Anthropic between Claude 3.5 Sonnet and GPT-4o, GPT-4o Mini's predecessor:
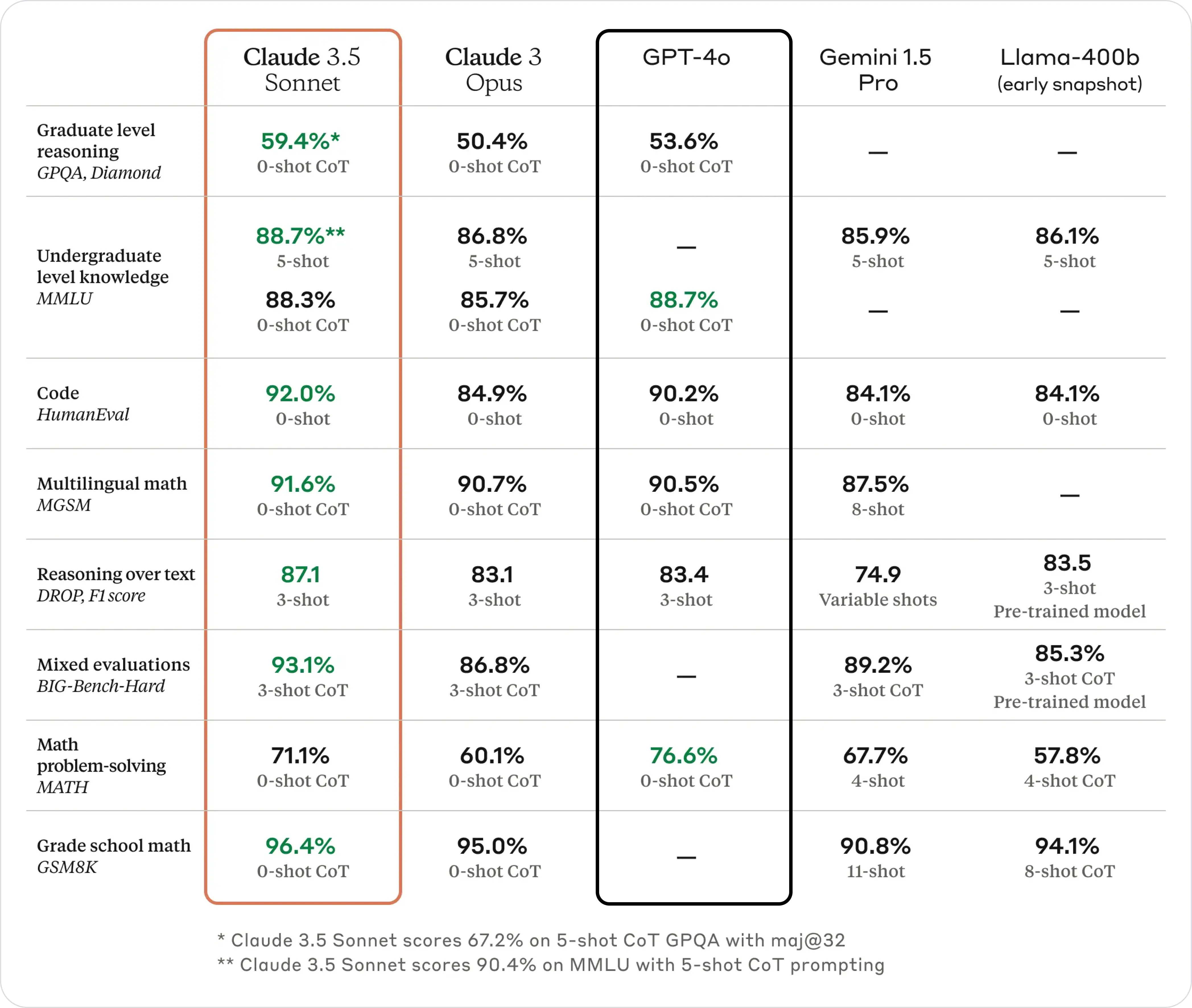
Claude 3.5 Sonnet demonstrates superior structured problem-solving capabilities, achieving 59.4% accuracy on zero-shot Chain of Thought (CoT) tasks. This performance sets new industry standards for its performance in graduate-level reasoning and complex query understanding.
GPT-4o achieved 53.6% accuracy on zero-shot CoT tasks, falling short of Claude 3.5 Sonnet in advanced reasoning despite being optimized for conversation flow and multimodal inputs.
In short, Claude 3.5 Sonnet is seen to perform better than GPT-4o in majority of key benchmarks, while GPT-4o performed better on the MATH benchmark, with a score of 76.6% compared to Claude 3.5 Sonnet's 71.1%.
Step 2: GPT-4o vs. GPT-4o Mini
When comparing GPT-4o Mini with GPT-4o, we can see that GPT-4o has better performance than GPT-4o Mini in all the benchmarks, as expected for larger models. However, GPT-4o Mini still performed better than top models prior to Claude 3.5 Sonnet release, as reported by OpenAI.
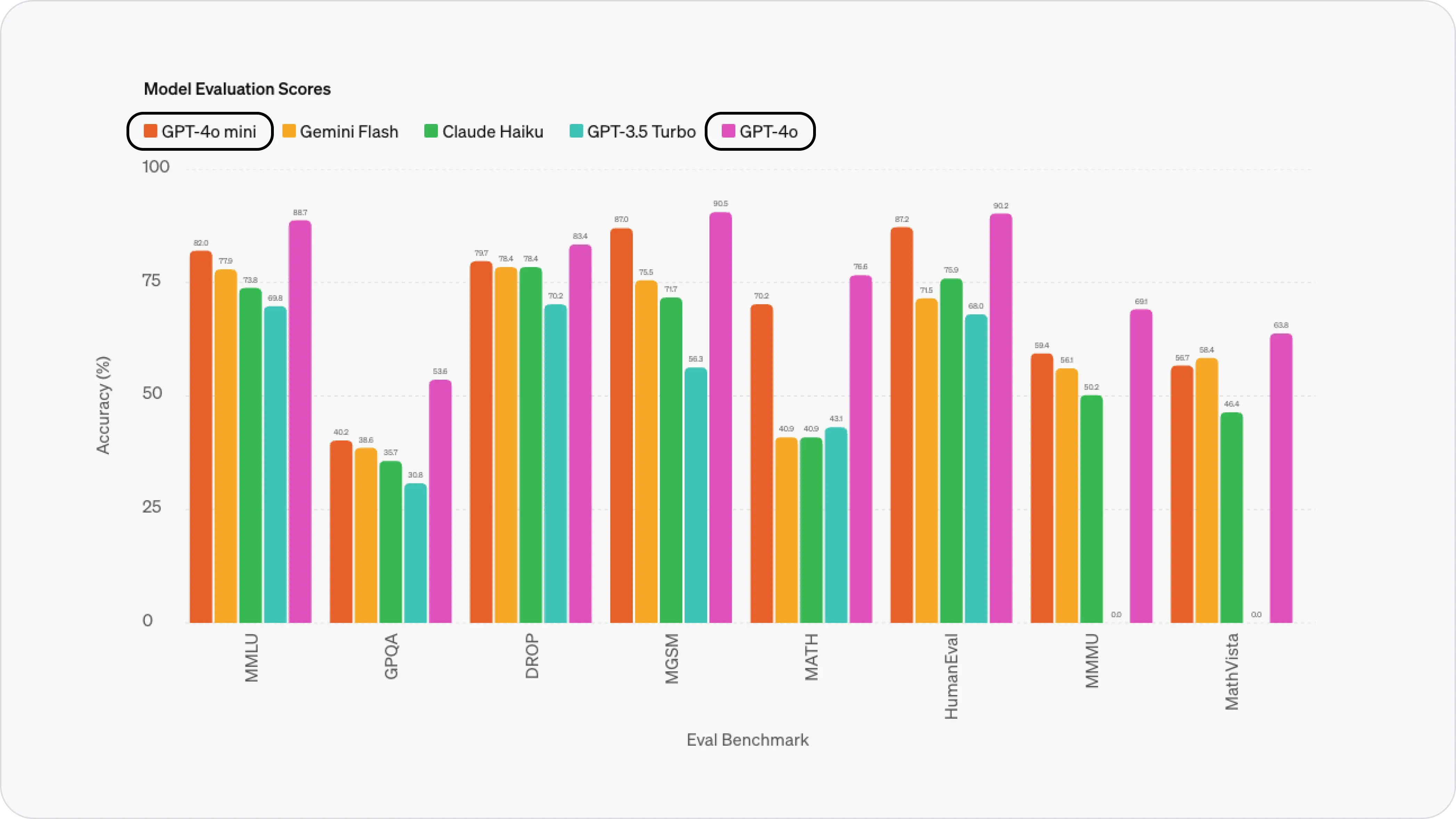
Finally, Claude 3.5 Sonnet vs. GPT-4o Mini
| gpt-4o mini | claude 3.5 sonnet | |
|---|---|---|
| MMLU | 82.0% | 88.7% (+6.7%) |
| GPQA | 40.2% | 59.4% (+19.2%) |
| DROP | 79.7% | 87.1% (+7.4%) |
| MGSM | 87.0% | 91.6% (+4.6%) |
| MATH | 70.2% | 71.1% (+0.9%) |
| HumanEval | 87.2% | 92.0% (+4.8%) |
| MMMU | 59.4% | 68.3% (+8.9%) |
| MathVista | 56.7% | 67.7% (+11.0%) |
Cost Considerations
GPT-4o Mini is more cost-effective than Claude 3.5 Sonnet, at $0.15 per million input tokens compared to $3 per million. This pricing difference is one of the main reasons why developers may choose GPT-4o Mini over Claude 3.5 Sonnet.
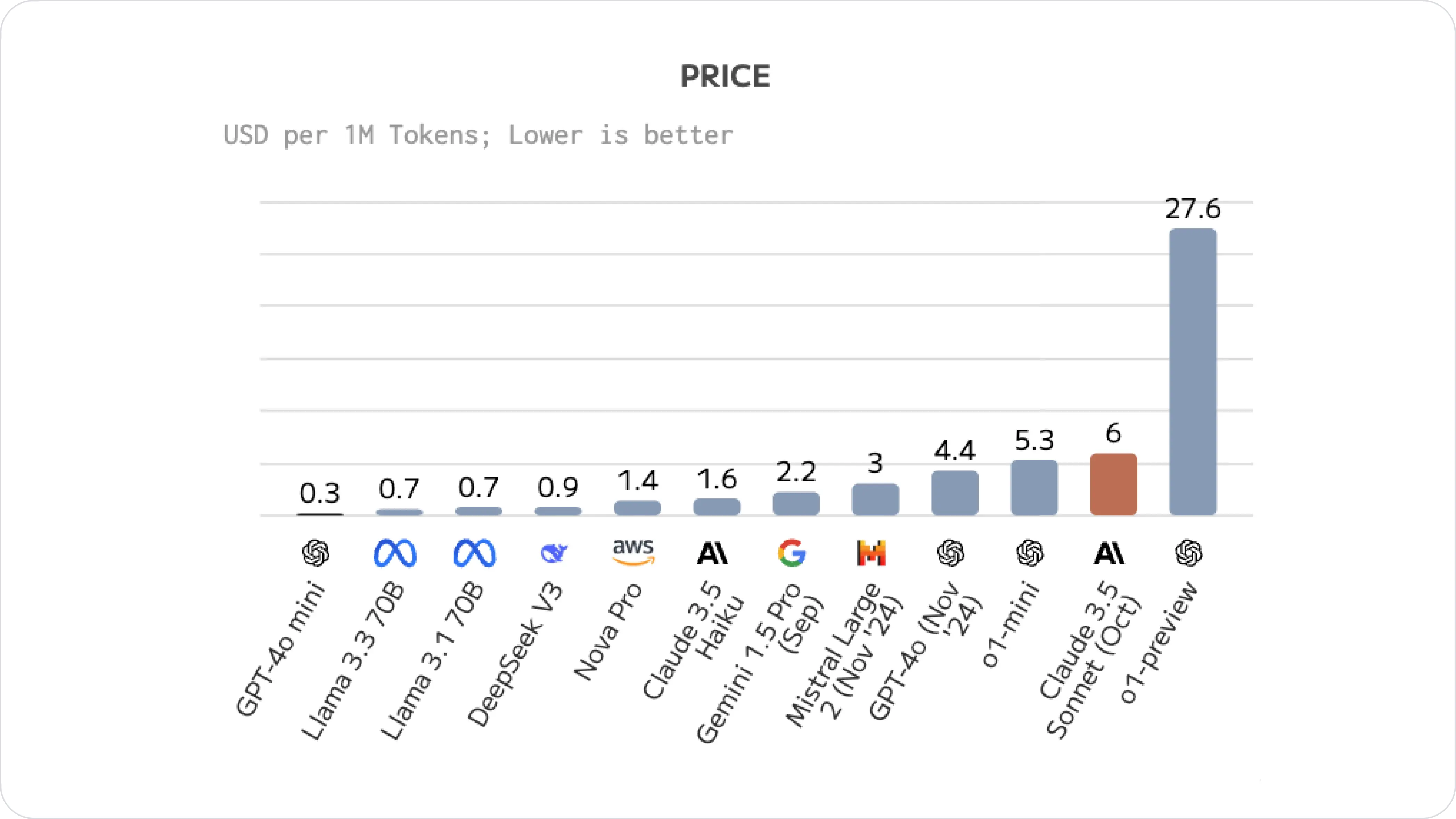
Image source: Quality, performance & price analysis
Using Claude? Save up to 70% on API costs ⚡️
Helicone users cache response, monitor usage and costs to save on API costs.
How Developers Are Saving Costs
Teams typically evaluate whether the performance gains of Claude 3.5 Sonnet justify its higher cost for their particular use cases, and decide to optimize their costs using a hybrid approach. For example:
- Selective model usage: Using Claude 3.5 Sonnet for complex tasks that require more advanced reasoning and GPT-4o Mini for routine operations.
- Hybrid approaches: Combining both models. Use GPT-4o Mini for initial processing and Claude 3.5 Sonnet for more complex reasoning.
- Optimizing input/output: Craft efficient prompts and monitor token usage with Helicone to reduce costs.
- Focusing on efficiency: Optimizing AI pipelines and preprocessing to reduce compute needs.
- Fine-tuning: Fine-tune GPT-4o Mini (
gpt-4o-mini-2024-07-18) for your specific use case if you don't need Claude 3.5 Sonnet's advanced capabilities.
💡 When to Use Fine-tuning
Fine-tuning GPT-4o Mini is a great way to save costs, but it requires a careful investment of time and effort. OpenAI recommends prompt engineering, prompt chaining and function calling first before jumping into fine-tuning.
Context Window Comparison
Claude 3.5 Sonnet
Maximum Context Window: 200,000 tokens
Claude's larger context window enables processing of extensive documents and maintaining coherence in long conversations. This makes it ideal for customer support and research applications requiring deep contextual understanding.
GPT-4o Mini
Maximum Context Window: 128,000 tokens
GPT-4o Mini's window, while smaller, still handles significant data volumes and excels at multimodal tasks. However, very large datasets may need segmentation to fit within its limits.
Key Differences
Claude 3.5 Sonnet's larger window makes it better suited for long-form content and extended dialogues. GPT-4o Mini focuses on efficiency for shorter interactions but requires more careful context management for larger datasets.
Speed Comparison
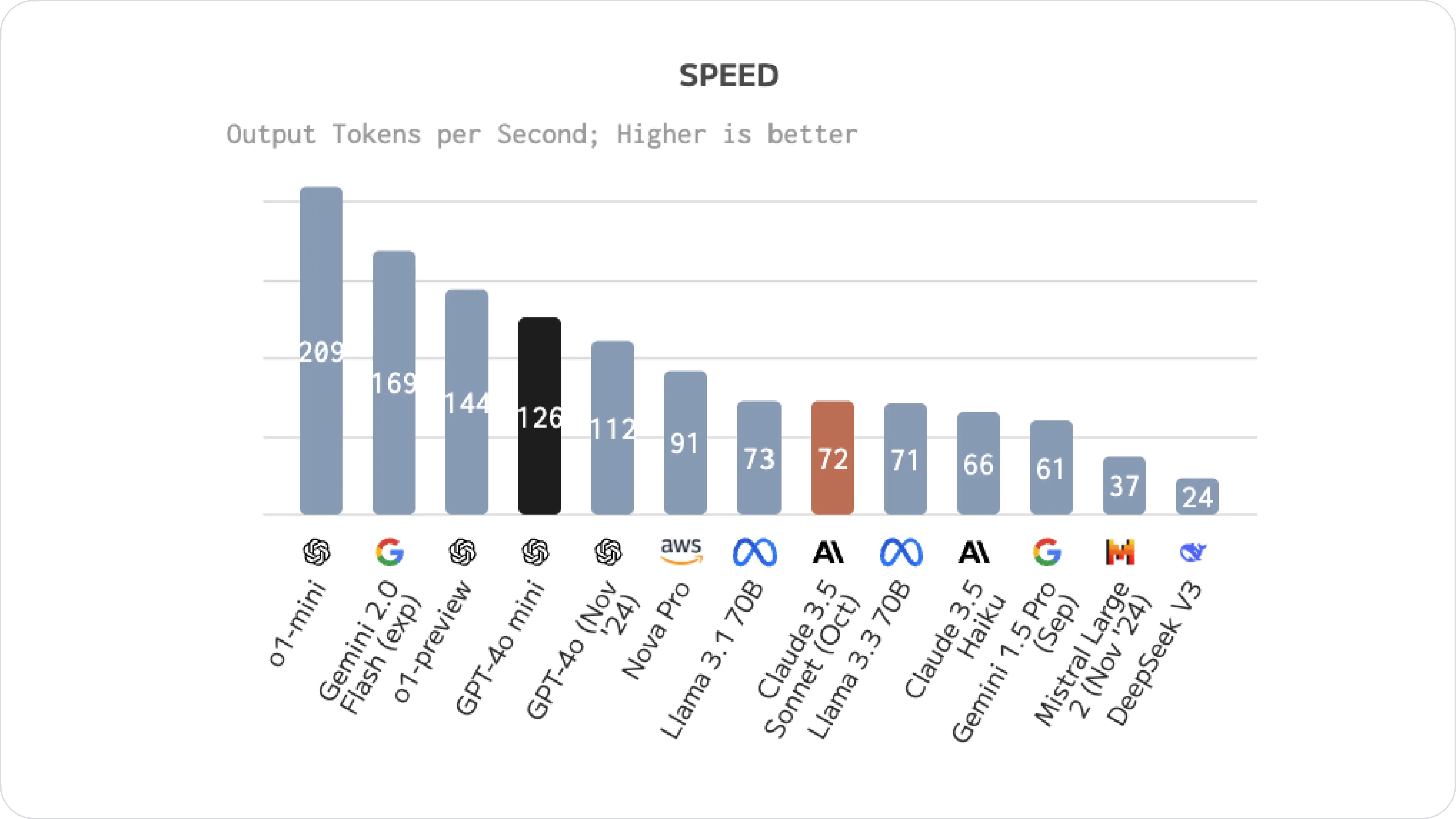
Image source: Quality, performance & price analysis
GPT-4o Mini produces more tokens per second than Claude 3.5 Sonnet, with 126 tokens/second compared to 72 tokens/second, making GPT-4o mini better suited for anything needing quick responses.
Developers have reported that GPT-4o Mini is just as fast as GPT-3.5 Turbo, but with a 60% reduction in cost. It's budget-friendly and outsmarts GPT-3.5 Turbo. If you're using GPT-3.5 Turbo, we recommend moving to GPT-4o Mini.
Code Generation
On the HumanEval code generation benchmark, Claude 3.5 Sonnet scores 92.0% compared to GPT-4o Mini's 87.2%, giving Claude a slight edge in code generation accuracy.
| Benchmark | GPT-4o Mini | Claude 3.5 Sonnet |
|---|---|---|
| MMLU Evaluating LLM knowledge acquisition in zero-shot and few-shot settings | 82.0 (5-shot) | 90.4 (5-shot CoT) |
| MMMU A wide ranging multi-discipline and multimodal benchmark | 59.4 | 68.3 (0-shot CoT) |
| HumanEval A benchmark to measure functional correctness for synthesizing programs from docstrings | 87.2 (0-shot) | 92.0 |
| MATH Benchmark performance on Math problems ranging across 5 levels of difficulty and 7 sub-disciplines | 70.2 (0-shot) | 71.1 (0-shot) |
In practical coding tasks, Claude 3.5 Sonnet efficiently generates multiple solutions with minimal prompting. GPT-4o Mini achieves similar results but may need more specific instructions.
Claude's Error Correction Capabilities
Claude 3.5 Sonnet excels at code error detection and correction, providing more thorough debugging assistance compared to GPT-4o Mini. This makes Claude particularly valuable for developers focused on code quality and troubleshooting.
Creative Tasks and Mathematical Reasoning
Claude excels in creative writing and brainstorming due to its nuanced understanding of context. GPT-4o Mini also performs well in creative tasks but benefits from its multimodal capabilities to enhance content generation across various formats.
On mathematical benchmarks, GPT-4o Mini leads with a score of 70.2%, while Claude follows with 71.1%. However, Claude outperforms GPT-4o Mini in visual math reasoning tasks, showcasing its strengths in specific areas of mathematical problem-solving.
Visual Reasoning in Claude 3.5 Sonnet
Claude 3.5 Sonnet's vision capabilities allow it to analyze images, interpret charts and graphs, and transcribe text from images. This makes it useful for medical imaging, retail, and logistics applications.
Multimodal Support
While both models are multimodal and support text and images, OpenAI plans to add support for audio and video inputs to GPT-4o Mini, making the model more versatile for multimedia applications. In contrast, Claude 3.5 Sonnet currently handles text and images but is focused on enhancing its reasoning and coding capabilities.
Choosing the Right Model
- Choose GPT-4o Mini for: Fast, cost-effective solutions, especially for customer-facing applications and multimedia processing
- Choose Claude 3.5 Sonnet for: Complex coding tasks, research analysis, and applications where accuracy and safety are paramount
Integrate your LLM app in seconds ⚡️
Start monitoring your Claude-3.5-Sonnet app or GPT-4o app with Helicone.
Bottom Line
For most developers and businesses, GPT-4o Mini offers better value with its faster response times and lower costs, making it ideal for production applications where speed and budget matter. Its performance nearly matches GPT-4 while being significantly more cost-effective, especially for conversational AI and multimedia tasks.
However, if your work requires high accuracy in code generation, complex reasoning, or handling sensitive data, Claude 3.5 Sonnet would be the better choice. Its superior performance in benchmarks and stronger safety features justify the higher cost for critical applications.
Other Related Comparisons
-
Claude 3.5 Sonnet vs. OpenAI o1
-
Llama 3.3 just dropped — is it better than GPT-4 or Claude-Sonnet-3.5?
-
Google Gemini Exp-1206 is Outperforming GPT-4o and O1
Questions or feedback?
Is the information out of date? Please raise an issue and we'd love to hear your insights!